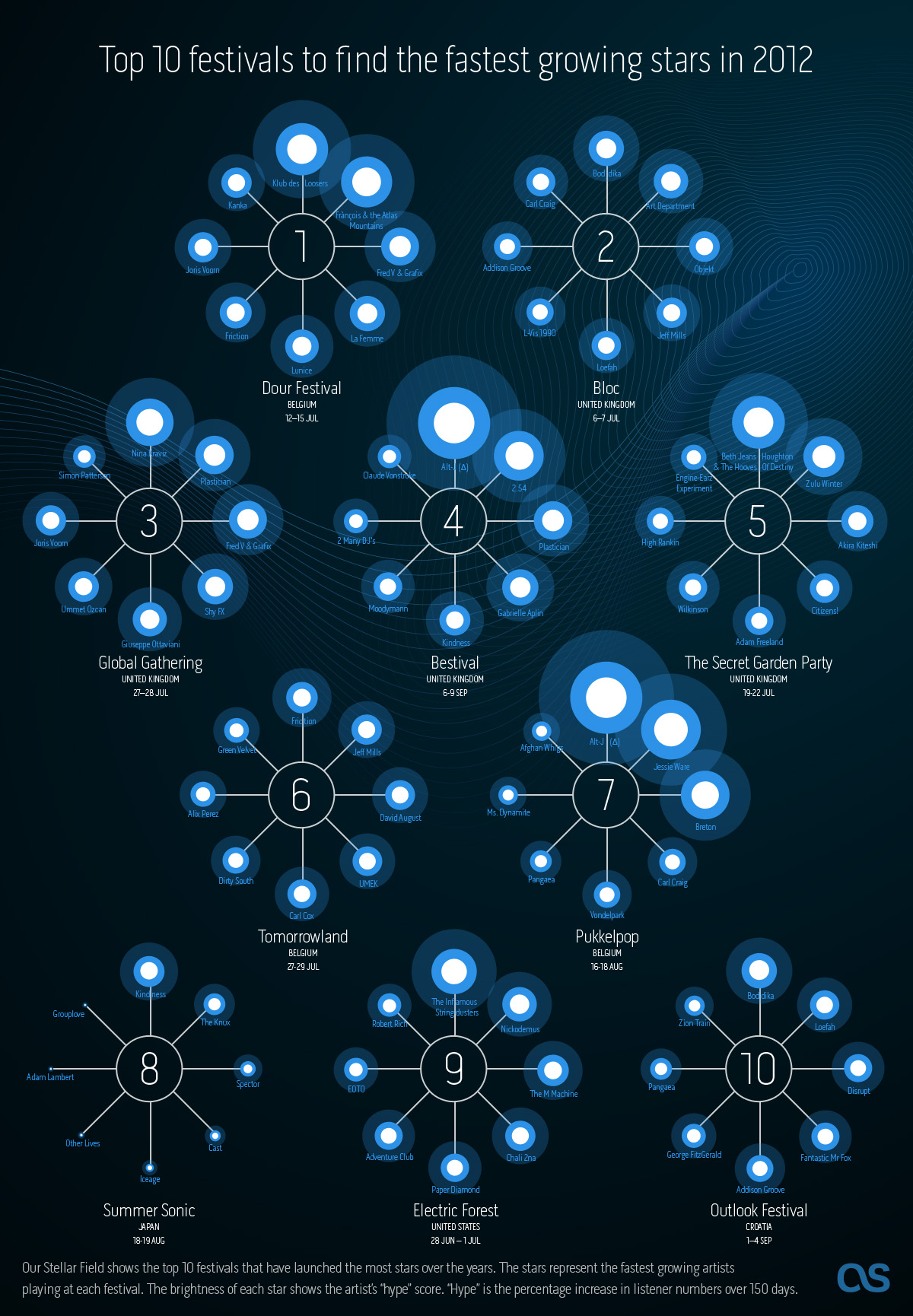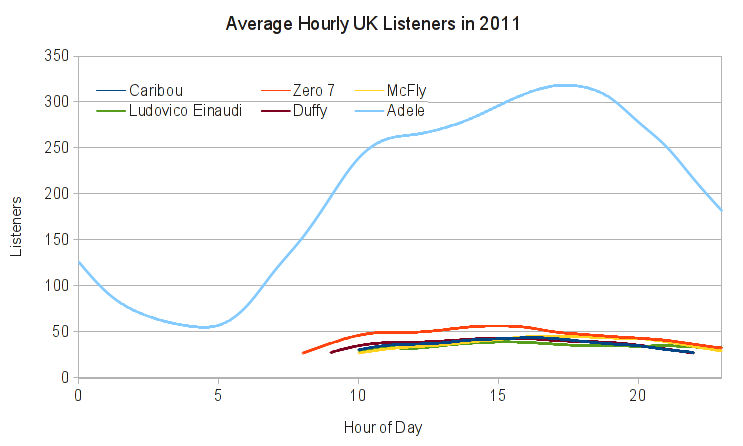
The open source tool balance is an essential part of the service infrastructure here at Last.fm. Multiple instances of balance are running on each and every web server node, on the various production back end servers, and also on our development machines. So at any given time there are probably thousands of instances running simultaneously on our machines.
What does it do?
balance is a so-called load balancer. It is generally used as a proxy to distribute a large number of incoming requests to a group of servers. In other words it is responsible for balancing the load between all the servers in a group. Quite often, load balancers are dedicated hardware products. However, balance is a software load balancer, which means it can just run as an additional program on any server.
In addition to load balancing, balance also supports a scheme called failover. This means you can define a second group of servers and balance will route requests to the second group if all servers in the first group fail. This failover scheme is used by most of our backend services at Last.fm. We usually have a main server and a backup server that kicks in once the main server fails.
End of story?
Certainly not! There are some subtleties in the use of balance that have given us headaches in the past. By far the biggest problem is that there are cases when failover just doesn’t work right in our environment. So here’s a real example…
One day we had to take down the main server for one of our backend services to replace a hard drive. The backup server was running fine and we relied on balance to take care of routing all requests through to the backup box. Unfortunately, shortly after the main server went down, we noticed that most requests to the service failed.
What had happened? balance has a configurable connect timeout, i.e. it tries to connect to a service and then waits for a certain amount of time until it figures out that it can’t connect. If the server machine is running, the connect will fail almost instantly if the service itself is unavailable. However, if the server is down, it’ll wait until the connect timeout has elapsed. So in our case, balance was trying to connect to the main server (which was down) and then waiting for 5 seconds before attempting to connect to the backup server. In the meantime, the client had already given up (it was using a much smaller timeout). balance would only notice that the client had given up by the time it had established the connection to the backup server. The next time the client tried to connect, the same thing would happen all over again.
But someone else would certainly have had the same problem before?
I’m quite sure of that. And I guess that’s what caused the autodisable feature to be added to balance. When this feature is being used, balance will automatically disable servers that it fails to connect to. The downside, though, is that there’s no way to automatically enable servers again. And manually enabling them isn’t really an option given the number of instances of balance we’re running and given that it could cause all servers to be permanently disabled in case of, for example, temporary network failure.
So what now?
We had to face the fact that in theory we had a really nice redundancy scheme, but it could fail quite miserably in practice. So I began to look around for alternatives to balance and found a couple of other open source load balancers. Sadly, all of them had either been abandoned by their authors, failed to build out of the box or just didn’t fulfill our requirements.
balance was actually just what we needed. The only thing it was missing was support for monitoring all back end connections and dynamically disabling and enabling them as they fail or pass the monitoring checks.
So eventually I started looking into adding exactly that functionality to balance.
balance.fm
Implementing monitoring for balance was relatively straightforward, even though it made me aware of how much I had gotten used to developing software in C++. With balance being written in pure C, I was really missing exception handling and the C++ standard library.
The amount of code changes was massive considering the rather small code base of balance. As of now, more than a thousand lines of code have changed and another thousand lines have been added. So we decided to fork the original project and rebrand it as balance.fm.
It took about a week to refactor the existing code and finally add the monitoring feature. Along the way of adding monitoring, quite a few bugs have been fixed as well (for details, just have a look at the commit log if you’re interested) and I hope these fixes make up for all the bugs that I’ve undoubtedly introduced by adding loads of new code.
The balance.fm code has since been reviewed by the MIR team here at Last.fm and is available from github.com/lastfm/balance.fm.
If you have an application for balance.fm, please give it a try and let us know what you think and like or dislike about it!