This is the second in a series of posts from the Last.fm engineering team covering the geekier aspects of our recent Last.fm on Xbox LIVE launch. Part one (“The War Room”) is here.
The music streaming architecture at Last.fm is an area of our infrastructure that has been scaling steadily for some time. The final stage of delivering streams to users fetches the raw mp3 data from a MogileFS distributed file system before passing it through our audio streaming software, which handles the actual audio serving. There are two main considerations with this streaming system: physical disk capacity, and raw IO throughput. The number of random IO operations a storage system can support has a big effect on how many users we can serve from it, so this number (IOPS) is a metric we’re very interested in. The disk capacity of the cluster has effectively ceased being a problem with the capacities available from newer SATA drives, so our biggest concern is having enough IO performance across the cluster to serve all our concurrent users. To put some numbers on this, a single 7200rpm SATA drive can produce enough IOPS to serve around 300 concurrent connections.
We’ve been using MogileFS for years at Last.fm, and it’s served us very well. As our content catalogue has grown, so has our userbase. As we’ve added storage to our streaming cluster, we’ve also been adding IO capacity in step with that, since each disk added into the streaming cluster brings with it more IOPS. From the early days, when our streaming machines were relatively small, we’ve moved up to systems built around the Supermicro SC846 chassis. These provide cost effective high-density storage, packing 24 3.5” SATA drives into 4U, and are ideal for growing our MogileFS pool.
Changing our approach
The arrival of Xbox users on the Last.fm scene pushed us to do some re-thinking on our approach to streaming. For the first time, we needed a way to scale up the IO capacity of our MogileFS cluster independently of the storage capacity. Xbox wasn’t going to bring us any more content, but was going to land a lot of new streaming users on our servers. So, enter SSDs…
Testing our first SSD based systems
We’d been looking at SSDs with interest for some time, as IO bottlenecks are common in any infrastructure dealing with large data volumes. We hadn’t deployed them in any live capacity before though, and this was an ideal opportunity to see whether the reality lived up to the marketing! Having looked at a number of SSD specs and read about many of the problems early adopters had encountered, we felt as though we were in a position to make an informed decision. So, earlier this year, we managed to get hold of some test kit to try out. Our test rig was an 8 core system with 2 X5570 CPUs and 12 Gb RAM (a SunFire X4170).

Into this, we put 2 hard disks for the OS, and 4 Intel X25-E SSDs.

We favoured the Intel SSDs because they’ve had fantastic reviews, and they were officially supported in the X4170. The X25-E drives advertise in excess of 35,000 read IOPS, so we were excited to see what it could do, and in testing, we weren’t disappointed. Each single SSD can support around 7000 concurrent listeners, and the serving capacity of the machine topped out at around 30,000 concurrent connections in it’s tested configuration – here it is half way through a test run (wider image here):
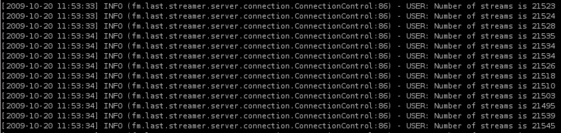
Spot which devices are the SSDs… (wider image here)
At that point its network was saturated, which was causing buffering and connection issues, so with 10GigE cards it might have been possible to push this configuration even higher. We tested both the 32Gb versions (which Sun have explicitly qualified with the X4170), and the 64Gb versions (which they haven’t). We ended up opting for the 64Gb versions, as we needed to be able to get enough content onto the SSDs for us to serve a good number of user requests, otherwise all that IO wasn’t going to do us any good. To get these performance figures, we had to tune the Linux scheduler defaults a bit:-
echo noop > /sys/block/sda/queue/scheduler
echo 32 > /sys/block/sda/queue/read_ahead_kb
This is set for each SSD – by default Linux uses scheduler algorithms that are optimised for hard drives, where each seek carries a penalty, so it’s worth reading extra data in while the drive head is in position. There’s basically zero seek penalty on an SSD, so those assumptions fall down.
Going into production
Once we were happy with our test results, we needed to put the new setup into production. Doing this involved some interesting changes to our systems. We extended MogileFS to understand the concept of “hot” nodes – storage nodes that are treated preferentially when servicing requests for files. We also implemented a “hot class” – when a file is put into this class, MogileFS will replicate it onto our SSD based nodes. This allows us to continually move our most popular content onto SSDs, effectively using them as a faster layer built on top of our main disk based storage pool.
We also needed to change the way MogileFS treats disk load. By default, it looks at the percentage utilisation figure from iostat, and tries to send requests to the most lightly-loaded disk with the requested content. This is another assumption that breaks down when you use SSDs, as they do not suffer from the same performance degradation under load that a hard drive does; a 95% utilised SSD can still respond many times faster than a 10% utilised hard drive. So, we extended the statistics that MogileFS retrieves from iostat to also include the wait time (await) and the service time (svctm) figures, so that we have better information about device performance.
Once those changes had been made, we were ready to go live. We used the same hardware as our final test configuration (SunFire X4170 with Intel X25-E SSDs), and we are now serving over 50% of our streaming from these machines, which have less than 10% of our total storage capacity. The graph below shows when we initially put these machines live.
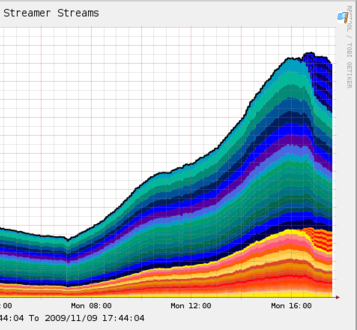
You can see the SSD machines starting to take up load on the right of the graph – this was with a relatively small amount of initial seed content, so the offload from the main cluster was much smaller than we’ve since seen after filling the SSDs with even more popular tracks.
Conclusions
We all had great fun with this project, and built a new layer into our streaming infrastructure that will make it easy to scale upwards. We’ll be feeding our MogileFS patches back to the community, so that other MogileFS users can make use of them where appropriate and improve them further. Finally, thanks go to all the people who put effort into making this possible – all of crew at Last.HQ, particularly Jonty for all his work on extending MogileFS, and Laurie and Adrian for lots of work testing the streaming setup. Also thanks to Andy Williams and Nick Morgan at Sun Microsystems for getting us an evaluation system and answering lots of questions, and to Gareth Tucker and David Byrne at Intel for their help in getting us the SSDs in time.
















{kind=link}