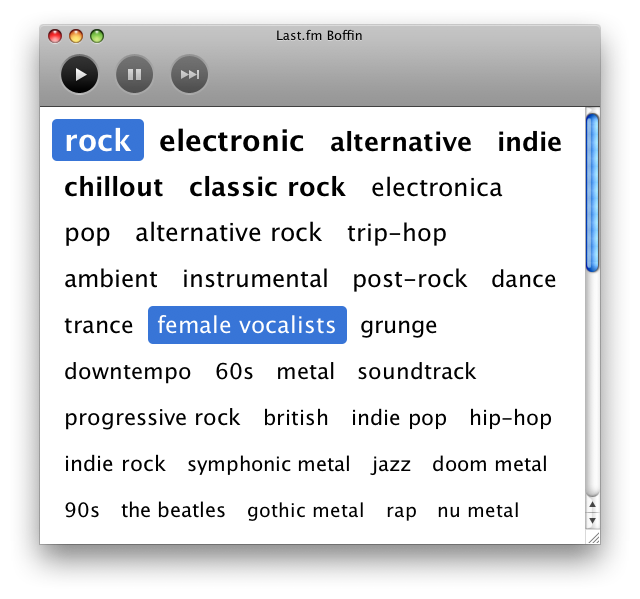
A week or so ago, on Sunday 14th December, we held our first open Hack Day, giving developers a chance to show off what they could build in a day with nothing but their wits and the Last.fm API.

At around 10:30, the hungry and cold developers started pouring into Corbet Place, behind Brick Lane in the heart of East London. With free food and drink behind the bar, plenty of comfy sofas to drape themselves over, and a Surface table with which to amuse themselves, the hackers dug in. (Sorry you guys had to wait in the cold for longer than we’d hoped, that sucked.)
By 6:30, and in spite of wifi woes throughout the day, we had 30 quick fire demos lined up to wow the assembled crowd of geeks. As anyone who’s run an event like this will attest, getting 30 odd laptops hooked up to 2 projector adaptors on rotation with a 2 minute turnaround is no mean feat, but no one was trampled underfoot and only one person outright gave up (apologies Steve!).
Amongst our favourite hacks were Bret Ehlert’s Nostalgia.fm, an app that creates playlists based on your historical charts so you can relive your headier musical days; Your Next Favourite Band by Utku Can and Phil Nash, which finds the band everyone’s listening to but you; and Neil Crosby’s Last Genius, a bookmarklet that builds a playlist using any track on Last.fm as the starting point.
We were extremely impressed with everyone’s work but after careful deliberation, we had to select three winners for the awesome prizes provided by Codeplex:
Rob Mckinnon walked away with a shiny XBox 360 for his work building Gig notifications with Growl. In his own words:
“Need help remembering to get gig tickets? This hack gives you local event notifications via Last.fm for the band you’re now playing. Implemented as Ruby script that uses last.fm api and growl notifications. Could be wrapped up as a Mac dashboard widget with a bit of work.”
Cameron Ross also snagged an XBox for the awesome Universal Scrobbler:
“This suite of tools allow you to scrobble songs from previously unscrobblable sources. There is a FireFox extension to allow scrobbling of songs listened on MySpace, a tool to browse MusicBrainz for albums and tracks to scrobble (for example for if you listen to an album in the car or CD player), a tool to scrobble songs retrospectively that you listened to on BBC Radio, and a tool to scrobble a custom song.”
David Padbury and Jamie Hollingworth stormed to win the grand prize of £1000 with Staff Wars.fm:
“StaffWars works by playing a user’s personal last.fm station communally to the office. When someone becomes offended by their colleague’s poor taste in music they initiate a challenge to take control of the office stereo from the current user. At this point StaffWars analyses the profiles of the competing users and looks for similar tastes in music. It will generate a small music quiz based on these similar tastes in music and ask it too both users. If the challenging user wins they will take control of the stereo otherwise the existing station will carry on playing.”
The day was rounded off with an excellent set from Hexstatic while the last free drinks were squeezed out of the bar.
Thanks again to those who came and made this event a success. I can’t wait for the next one!
We’ll try to keep this list updated with all the other hacks as info comes in, let us know if we’re missing you.
More photos from the day, courtesy Russ and Dimi.